
大语言模型(LLM)自2022年11月30日ChatGPT发布以来,持续引起AI应用的热点关注, 2023年的LLaMa2的开源发布,更加推波助澜地掀起了各类应用大模型的发展,各研究团队的你争我赶地追最佳智能排名,各应用链接框架也随之发展, 相关的商业应用生态系统正在高速发展中。
若想入门了解大语言模型, 首先是先熟悉体验一下各大语言模型(LLM)的能力, 比较方便的方法是使用网页对话的界面,最好还能选择跟不同模型应用(Bot)来对话, 了解各模型的专长和特点, 例如某些模型对于写代码、分析代码比较擅长;有些模型适合画图创意;有些模型适合逻辑推理,回答商业问题;有些适合起草文稿等等。
- 大语言模型市集
推荐使用这个大语言模型的市集站点: www.poe.com 它将当前主流的模型都汇集在一起, 包括付费版和免费版, 对入门来说,大部分情况下免费版就够用了。
使用POE先要注册后登录, 可使用Google 或 Apple 帐号登录,也可以自行电邮注册后使用。
成功登录后进入主界面, 左边是菜单选项, 右边是提示栏(Prompt),直接可是输入你想要问AI的问题, 开启对话模型.

例如输入提示词: please explain the algebra to primary school students, please answer with Simplified Chinese

也可以在左边选取更多的其他模型(Bots)

- 当前流行模型介绍
- ChatGPT 是OpenAI发布的对话模型, 当前ChatGPT 3.5是可以免费使用, ChatGPT4.0 是需要订阅付费的。 普遍认为GPT4.0 是目前最高“智能”水准 (State of the Art)。其中免费的GPT-3.5-Instruct是指令式的对话模型, 能较好地根据用户指示来生成用户所期望的结果。
- Llama系列模型是开源模型, 比较出名的有Llama官方系列的各种大小模型,以及针对代码编程模型(Code-Llama) , 也有Mixtral系列模型, 来自法国的公司,根据实际使用效果,可认为接近ChatGPT4.0 的能力, 是免费模型中的佼佼者之一。
- 图像生成模型 有 MidJounery 和 StableDiffusion 两者能力可以说是叮当码头。
- Claude系列模型是由原OpenAI公司骨干出去创办的Anthropic公司发布, 宣传报告显示全面超越了GPT4.0, 可以看到大语言模型当前高速发展、激烈竞争的态势。
- 大模型的使用方式
大语言模型除了通过网页方式对话, 也部分APP软件提供对话界面使用, 主流的几个大模型也提供网络API接入的方式使用, 这样方便与已有的应用程序对接, 例如客服中心Call Center等。
- 大模型本地部署
本质上来说大模型分为训练大模型和使用大模型, 训练大模型需要强大的算力、训练数据(语料库)等工程能力, 基本上是大型公司和有实力的研究机构才能完成。 使用大模型则不同,仅是如何更好地利用已训练好的模型,对算力的要求大幅度降低。
自LLama2开源和开放商用许可后, 大语言模型在企业或机构本地化部署成为可能,存托和发布模型的市集 Huggineface 涌现出各种可下载的模型,这些发布的模型可以下载到本地,使用本地的大模型解释器来运行。
当前主流的几个本地大模型解释器工具有:
可安装本地大模型解释器, 下载几个较小的模型来本地体验一下。
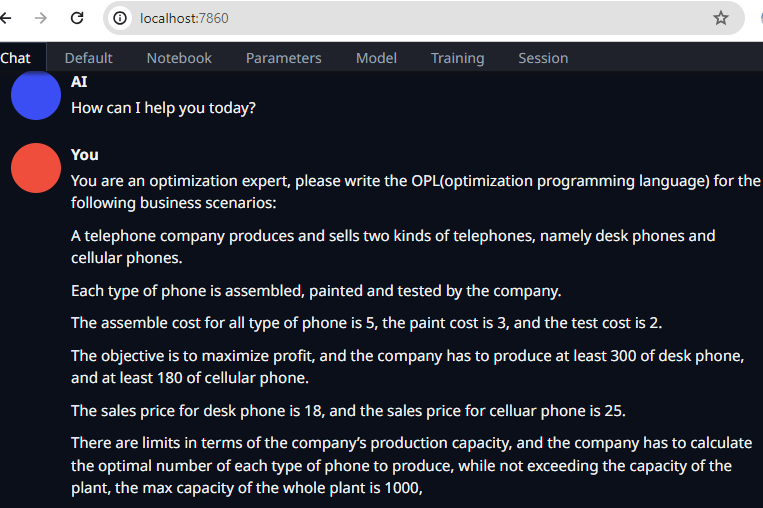
下面我就来试试一个经典的生产制造决策问题:
一家电话公司生产和销售两种电话,即台式电话和移动电话。
每种类型的手机均由该公司组装、喷漆和测试。
所有类型手机的组装成本为 5,油漆成本为 3,测试成本为 2。
目标是利润最大化,公司必须生产至少300部桌面电话,以及至少180部移动电话。
台式电话的销售价格为 18,移动电话的销售价格为 25。
公司的产能是有限制的,公司要计算出每种型号手机的最佳生产数量,同时不能超过工厂的产能,整个工厂的最大产能是1000部。
我向本地部署的LLM模型提问:
本地LLM的回答:
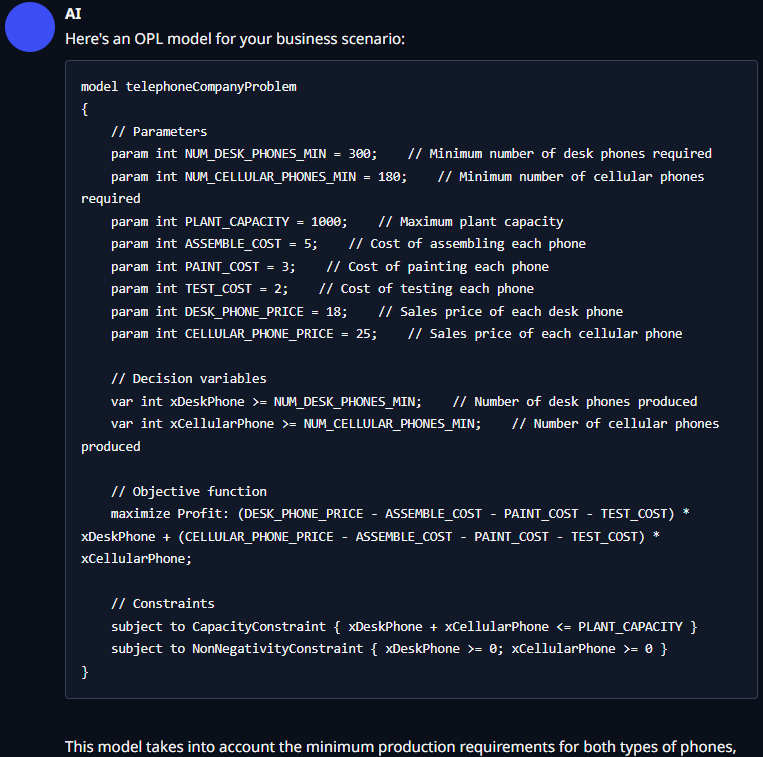
该模型考虑了两种类型手机的最低生产要求、最大工厂产能以及与组装、喷漆和测试每部手机相关的成本。 它还考虑每种类型手机的销售价格,以实现利润最大化。 该模型包括对工厂产能、生产数量非负性的约束,并确保至少按照场景中指定的方式生产每种类型的最小数量的手机。
妥妥的代码可以在支持OPL引擎的求解优化器上执行, 例如CPLEX。
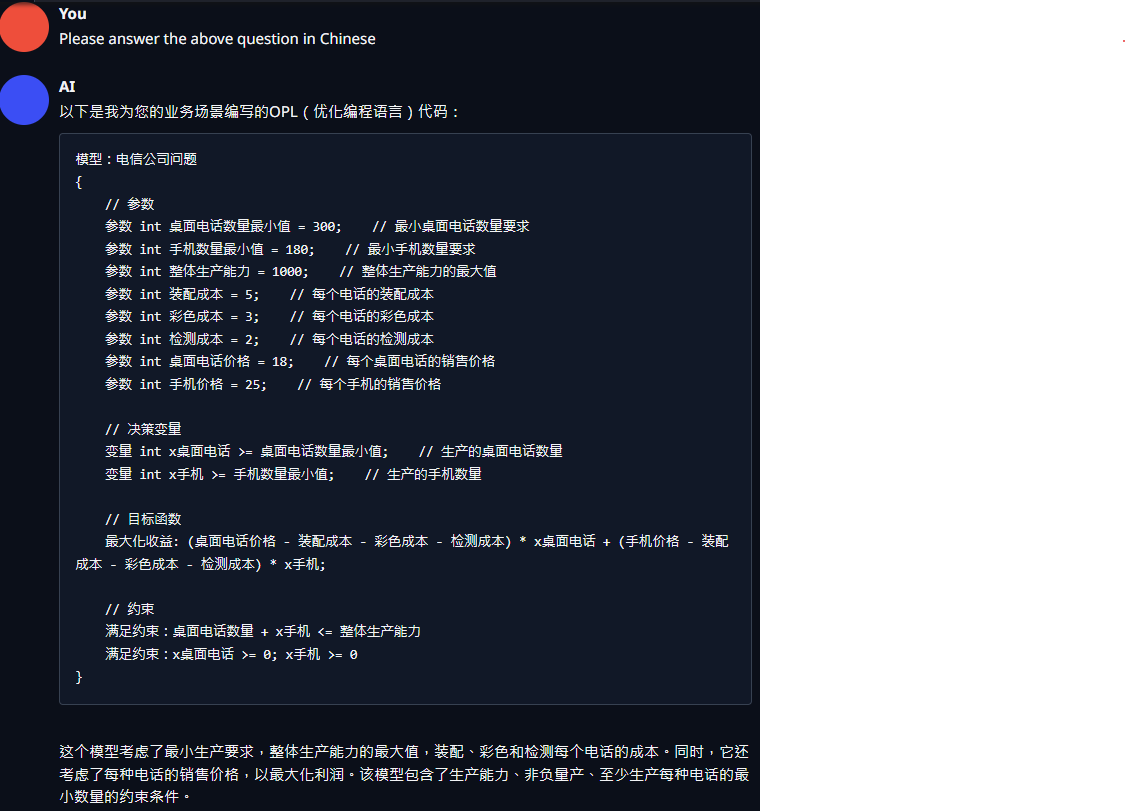
若有些朋友说,“那些都是英文,中文有哪些不一样呢”。
恩,中文确实有点不一样,中文的博大精深表达(一词多义, 一句多意等)增加了训练LLM大模型的难度, 但知识就是知识,语言只是承载,可以用英文来训练获得知识,然后用中文来表达知识,例如:上述的举例让AI用中文来回答:
至此我们可以有个初步的大语言模型的应用体验了。